04_HTTP 协议
1到6节课,讲的都是概念,多看几遍看懂就行。从第7节开始讲解创建http服务,http模块是一个非常重要的模块,因为像express库、koa库等都是对http库的封装而已,自己完全可以使用http模块创建一个服务器。
1.概念
HTTP(hypertext transport protocol)协议;中文叫超文本传输协议。




是一种基于TCP/IP的应用层通信协议,这个协议详细规定了 浏览器 和万维网 服务器 之间互相通信的规则。
协议中主要规定了两个方面的内容:
- 客户端:用来向服务器发送数据,可以被称之为请求报文
- 服务端:向客户端返回数据,可以被称之为响应报文
报文:可以简单理解为就是一堆字符串
2.请求报文的组成
看报文专业利器,先安装fiddle,老师的资料中有。
提示:
虽然在Chrome浏览器的F12中可以很清楚的看到请求报文、响应报文,但是有些情况下,还是需要外部的软件来查看,什么情况呢?比如说我之前做的支付项目,进入到一个界面之后,自动展示支付宝的formdata,而浏览器url一换之后,之前的请求就消除了,看不到了,只能看到支付宝的请求信息。
那么通过fiddle这类的工具,在这种情况下,就可以一直监听,得到想要的内容。

fiddle软件直接安装即可,等不用了就删除掉。fiddle安装后不会产生桌面图标,在win里面找一下fiddle,打开。
弹窗不用管,直接点否。首先进行配置,tools→options→https,进行配置,配置完成后,重启fiddle。







- 请求行
- 请求头
- 空行
- 请求体
后面会具体说明这些内容。
3.HTTP 的请求行







请求方法(get、post、put、delete等)
请求 URL(统一资源定位器)。例如:http://www.baidu.com:80/index.html?a=100&b=200#logo
- http: 协议(https、ftp、ssh等)
- www.baidu.com 域名(或主机名)
- 80 端口号
- /index.html 路径
- a=100&b=200 查询字符串
- #logo 哈希(锚点链接)
HTTP协议版本号
4.HTTP 请求头

格式:『头名:头值』
常见的请求头有:
| 请求头 | 解释 |
|---|---|
| Host | 主机名 |
| Connection | 连接的设置 keep-alive(保持连接);close(关闭连接) |
| Cache-Control | 缓存控制 max-age=0 (没有缓存) |
| Upgrade-Insecure-Requests | 将网页中的http请求转化为https请求(很少用),比如老网站升级 |
| User-Agent | 用户代理,客户端字符串标识,服务器可以通过这个标识来识别这个请求来自哪个客户端,一般在PC端和手机端的区分 |
| Accept | 设置浏览器接收的数据类型 |
| Accept-Encoding | 设置接收的压缩方式 |
| Accept-Language | 设置接收的语言 q=0.7 为喜好系数,满分为1 |
| Cookie | 后面单独讲 |
上面的只是常见的请求头,能记多少是多少,在创建服务器时会用到这些设置,边做边记。具体的请求头含义可以参考:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers
5.HTTP 的请求体

请求体内容的格式是非常灵活的,
(可以是空)==> GET请求,
(也可以是字符串,还可以是JSON)===> POST请求
例如:
- 字符串:keywords=手机&price=2000
- JSON:{"keywords":"手机","price":2000}
6.响应报文的组成·










- 响应行
xxxxxxxxxx11HTTP/1.1 200 OK
HTTP/1.1:HTTP协议版本号
200:响应状态码 404 Not Found 500 Internal Server Error。还有一些状态码,参考:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
OK:响应状态描述
响应状态码和响应字符串关系是一一对应的。
- 响应头
不需要把每一个都记住,记住常用的就行了。参考:https://developer.mozilla.org/zh-CN/docs/Glossary/Response_header
xxxxxxxxxx41Cache-Control:缓存控制 private 私有的,只允许客户端缓存数据2Connection 链接设置3Content-Type:text/html;charset=utf-8 设置响应体的数据类型以及字符集,响应体为html,字符集为utf-84Content-Length:响应体的长度,单位为字节
- 空行
- 响应体
响应体内容的类型是非常灵活的,常见的类型有 HTML、CSS、JS、图片、JSON
网络基础概念
IP











IP的分类










端口





7.创建 HTTP 服务
使用 nodejs 创建 HTTP 服务
7.1 操作步骤
xxxxxxxxxx141//1. 导入 http 模块2const http = require('http');34//2. 创建服务对象 create 创建 server 服务5// request 意为请求. 是对请求报文的封装对象, 通过 request 对象可以获得请求报文的数据6// response 意为响应. 是对响应报文的封装对象, 通过 response 对象可以设置响应报文7const server = http.createServer((request, response) => {8 response.end('Hello HTTP server');// 设置响应体,并结束相应。9});1011//3. 监听端口, 启动服务12server.listen(9000, () => {// 回调函数在服务启动成功后执行。13 console.log('服务已经启动, 端口 9000 监听中...');14});http.createServer 里的回调函数的执行时机:
当接收到 HTTP 请求的时候,就会执行
7.2 测试
浏览器请求对应端口
xxxxxxxxxx11http://127.0.0.1:9000

7.3 注意事项
- 命令行
ctrl + c,可以停止服务 - 当服务启动后,更新代码之后,
必须重启服务才能生效 - 响应内容中文乱码的解决办法
当响应内容有中文时,会产生乱码:
xxxxxxxxxx101const http = require("http");23const server = http.createServer((request, response) => {4 response.end("中文")5});67server.listen(9000, () => {8 console.log("服务已经启动,监听9000端口中");9});10
需要设置响应头:
xxxxxxxxxx11response.setHeader('content-type','text/html;charset=utf-8');xxxxxxxxxx101const http = require("http");23const server = http.createServer((request, response) => {4 response.setHeader("content-type", "text/html;charset=utf-8");5 response.end("中文");6});78server.listen(9000, () => {9 console.log("服务已经启动,监听9000端口中");10});

- 端口号被占用
xxxxxxxxxx11Error: listen EADDRINUSE: address already in use :::9000
解决办法:
1)关闭当前正在运行监听端口的服务 ( 使用较多,一般是自己在调试的时候不小心多次启动服务器了,所以可以这样做。真正的生产环境肯定是不能这么做的,要被别人叼。 )
2)修改其他端口号
- HTTP 协议默认端口是 80 。HTTPS 协议的默认端口是 443, HTTP 服务开发常用端口有 3000,8080,8090,9000 等
如果端口被其他程序占用,可以使用
资源监视器(按win→windows管理工具→资源监视器) 找到占用端口的程序的PID,然后使用任务管理器关闭对应的程序。


8.浏览器查看 HTTP 报文
点击步骤

8.1 查看请求行与请求头

8.2 查看请求体

8.3 查看 URL 查询字符串

8.4 查看响应行与响应头

8.5 查看响应体

9.获取 HTTP 请求报文
获取请求报文和设置响应报文,老师都是用一个一个例子讲解的,并不难,但是很琐碎,不好记笔记。觉得重要的我会记下来,但是复习的时候,还是一个个的输出看一下。在请求时可以直接在url后面拼接query参数,来模拟。
主要还是在http.createServer({})里面输出不同的语法规则来学习。
想要获取请求的数据,需要通过 request 对象。
| 含义 | 语法 | 重点掌握 |
|---|---|---|
| 请求方法 | request.method | * |
| 请求http版本 | request.httpVersion | |
| 请求路径 | request.url | * |
| URL 路径 | const url = require("url") url.parse(request.url).pathname | * |
| URL 查询字符串 | const url = require("url") url.parse(request.url,true).query | * |
| 请求头 | request.headers | * |
| 请求体 | request.on('data',function(chunk){}) request.on('end',function(){}) |
因为get请求的请求体一般是空的,所以需要使用form表单来搭建一个post请求。(但是在复习的时候就没有必要这么做了,因为比较麻烦,所以还是用apifox来发起请求方便些。)
xxxxxxxxxx151<html lang="en">3<head>4 <meta charset="UTF-8">5 <meta name="viewport" content="width=device-width, initial-scale=1.0">6 <title>Document</title>7</head>8<body>9 <form action="http://127.0.0.1:9000" method="post">10 <input type="text" name="username">11 <input type="text" name="password">12 <input type="submit" value="提交">13 </form>14</body>15</html>用open with live server打开,发起请求,这样我们设置的服务器中就可以看到请求体了。
注意事项:
- request.url 只能获取路径以及查询字符串,无法获取 URL 中的域名以及协议的内容
其实看到这句话,我还是有点懵的,路径以及查询字符串是什么?看一下前面的内容就知道了。

- request.headers 将请求信息转化成一个对象,并将属性名都转化成了『小写』
- 关于路径:如果访问网站的时候,只填写了 IP 地址或者是域名信息,此时请求的路径为『
/』 - 关于 favicon.ico:这个请求是属于浏览器自动发送的请求
- 解析url路径和字符串,node@18之后不建议使用url.parse,而是使用URL类。
xxxxxxxxxx131const http = require("http");23const server = http.createServer((request, response) => {4 // 可以查看nodejs的官方文档,URL模块,里面推荐使用URL的下列方法。因为new URL()里面必须是一个完整的URL,而request.url只是路径和查询字符串,所以需要拼接上协议名、域名、端口号(真实环境下需要真实的协议名、域名吗?不需要,只需要拼接上即可,因为我们解析的是request.url)。可以写在第二个参数上,可以采用默认的80端口(这样就可以省略不写)。5 let url = new URL(request.url, "http://127.0.0.1");6 console.log(url);7 8 response.end("url new method");9});1011server.listen(9000, () => {12 console.log("服务已经启动,监听9000端口中");13});浏览器输入http://127.0.0.1:9000/search?keyword=123看一下效果。

我只请求了一次啊,为什么会返回两个URL呢?因为下面这个favicon.ico是无论哪个网站都会默认请求的,不需要管。
xxxxxxxxxx181const http = require("http");23const server = http.createServer((request, response) => {4 // 可以查看nodejs的官方文档,URL模块,里面推荐使用URL的下列方法。因为new URL()里面必须是一个完整的URL,而request.url只是路径和查询字符串,所以需要拼接上域名、协议名、端口号(真实环境下需要真实的域名、协议名吗?不需要,只需要拼接上即可,因为我们解析的是request.url)。可以写在第二个参数上,可以采用默认的80端口(这样就可以省略不写)。5 let url = new URL(request.url, "http://127.0.0.1");6 console.log(url);7 // 获取路径8 let pathname = url.pathname;9 // 获取查询字符串10 let keyword = url.searchParams.get("keyword");11 console.log(pathname, " ", keyword);12 response.end("url new method");13});1415server.listen(9000, () => {16 console.log("服务已经启动,监听9000端口中");17});18
9.1 练习
按照以下要求搭建 HTTP 服务
| 请求类型(方法) | 请求地址 | 响应体结果 |
|---|---|---|
| get | /login | 登录页面 |
| get | /reg | 注册页面 |
xxxxxxxxxx231//1、引入http模块2const http = require("http");34//2、建立服务5const server = http.createServer((request,response)=>{6 // 这里为什么不使用new URL了?因为题目的要求完全可以通过解构 request 来解决,接口请求的时候没有携带参数,request.url就是请求路径。7 let {url,method} = request; //对象的解构赋值8 //设置响应头信息9 //解决中文乱码10 response.setHeader("Content-Type","text/html;charset=utf-8")11 if(url == "/register" && method == "GET"){12 response.end("注册页面");13 }else if(url=="/login" && method == "GET"){14 response.end("登录页面");15 }else{16 response.end("<h1>404 Not Found</h1>")17 }18})1920//3、监听端口21server.listen(8000,()=>{22 console.log('服务启动中....');23})我自己写的答案:
xxxxxxxxxx281const http = require("http");23const server = http.createServer((request, response) => {4 // 解决中文乱码5 response.setHeader("content-type", "text/html;charset=utf-8");6 // 获取请求报文相关信息7 const { method, url } = request;8 // 用新方法来获取URL上面的信息9 let newURL = new URL(url, "http://127.0.0.1");10 let pathname = newURL.pathname;1112 // 根据题目需求来做判断13 if (method === "GET") {14 if (pathname === "/login") {15 response.end("登录页面");16 } else if (pathname === "/reg") {17 response.end("注册页面");18 } else {19 response.end("Not Found");20 }21 } else {22 response.end("Not Fount");23 }24});2526server.listen(9000, () => {27 console.log("服务器启动了,端口号9000,监听中...");28});小节:
其实学到这里,我就感觉很高兴了,因为我终于弄清楚前后端分离应该怎么做了,部分原理总算弄明白了,也知道前后端不分离可以怎么做了。就是利用URL的不同来达到不同的目的,前端部分用一个url,后端部分用一个url,即使前后端部署到同一个主机上,那么也可以利用端口号的不同,来实现通信。这样即使前端url和后端url的路径有重名情况,也不会有任何影响,真的是感叹人类智慧的无限。
另外:
在调试后端url的时候,我们是直接在浏览器的地址栏中输入的url,返回的结果会直接显示在浏览器界面中,但其实我一直以来用的前后端分离技术,是前端先调用后端url,获取数据,然后将处理好的数据渲染到界面上。那么直接在浏览器中输入后端url并返回后端数据,有没有作用呢?应该有作用,这就是服务端渲染的技术,等我学nextjs的时候,可以看到,现在先不管。到时候可以看一下浏览器输入的是前端url还是直接输入后端url,我感觉应该还是前端url,因为前后端的端口号不同,别人在使用的时候,不一定会特意记住端口号的不同。(不应该这么说:“在浏览器里面输入后端url”,不应该是这样的,只不过是在我学习的时候是在浏览器中输入后端url。真正的项目还是应该前端来请求接口,只不过后端返回的直接是一个html页面,可以直接渲染到页面上,避免了前端的一些处理会更快一些。)
10.设置 HTTP 响应报文
注意老师的用词,对HTTP请求报文,是“获取”,对HTTP响应报文,是“设置”,意味着不同的操作。
| 作用 | 语法 |
|---|---|
| 设置响应状态码 | response.statusCode |
| 设置响应状态描述 | response.statusMessage (用的非常少) |
| 设置响应头信息 | response.setHeader('头名','头值') |
| 设置响应体 | response.write('xx') response.end('xx') |
xxxxxxxxxx121// 1、设置相应状态码,状态码200是默认的,所以之前的服务器都没有设置2response.statusCode = 201;34///2、设置响应状态描述,这个一般不要改,因为statusMessage的内容是和statusCode对应的,我改了别人反而不知道是什么情况了。其实在nestjs中,都会专门编写一个文件来规定code对应的message,照抄即可。5response.statusMessage = "hello"67///3、设置响应头8response.setHeader("content-type","text/html;charset=utf-8");9// 可以设置自定义的响应头10response.setHeader("myHeader","abc");11// 设置同名的响应头,比如说后面会学到的set-cookie,第二个参数是数组,可以从F12网络请求里面看到12response.setHeader("set-cookie",["a","b","c"])

xxxxxxxxxx111// 4、设置响应体2//write 和 end 的两种使用情况:34//1. write 和 end 的结合使用,适用于响应体相对分散的情况5response.write('xx');6response.write('xx');7response.write('xx');8response.end(); // 每一个请求,在处理的时候必须要执行 end 方法。一般来说,如果write和end一起使用,end里面不再设置响应体,只起到结束响应的作用,这是一种约定。910//2. 单独使用 end 方法,适用于响应体相对集中的情况11response.end('xxx');10.1 练习
搭建 HTTP 服务,响应一个 4 行 3 列的表格,并且要求表格有 隔行换色效果 ,且 点击 单元格能 高亮显示。
分析:题目需求其实是,服务端返回的是一个HTML文件的内容,里面有表格,并且里面可以编写css和js来实现样式和功能,那么可以使用模板字符串来编写html代码。可能为单元格绑定点击事件有点难度,因为一直都没有使用dom操作来绑定事件,搜索一下就知道了。
xxxxxxxxxx541//导入 http 模块2const http = require('http');34//创建服务对象5const server = http.createServer((request, response) => {6 response.end(`7 <!DOCTYPE html>8 <html lang="en">9 <head>10 <meta charset="UTF-8">11 <meta http-equiv="X-UA-Compatible" content="IE=edge">12 <meta name="viewport" content="width=device-width, initial-scale=1.0">13 <title>Document</title>14 <style>15 td{16 padding: 20px 40px;17 }18 table tr:nth-child(odd){19 background: #aef;20 }21 table tr:nth-child(even){22 background: #fcb;23 }24 table, td{25 border-collapse: collapse;26 }27 </style>28 </head>29 <body>30 <table border="1">31 <tr><td></td><td></td><td></td></tr>32 <tr><td></td><td></td><td></td></tr>33 <tr><td></td><td></td><td></td></tr>34 <tr><td></td><td></td><td></td></tr>35 </table>36 <script>37 //获取所有的 td38 let tds = document.querySelectorAll('td');39 //遍历40 tds.forEach(item => {41 item.onclick = function(){42 this.style.background = '#222';43 }44 })45 </script>46 </body>47 </html>48 `); //设置响应体49});5051//监听端口, 启动服务52server.listen(9000, () => {53 console.log('服务已经启动....')54});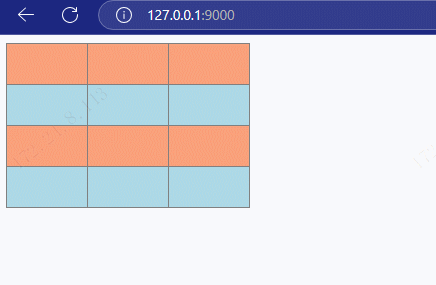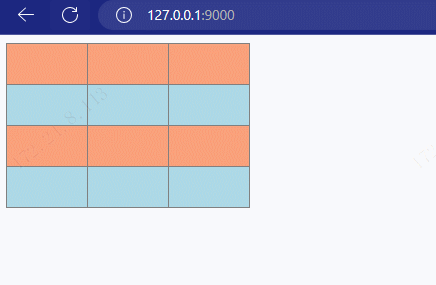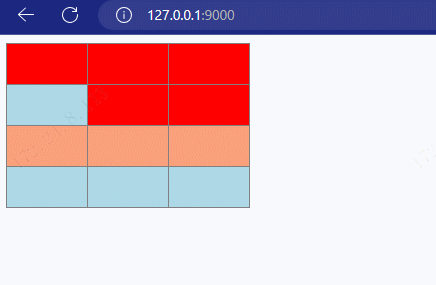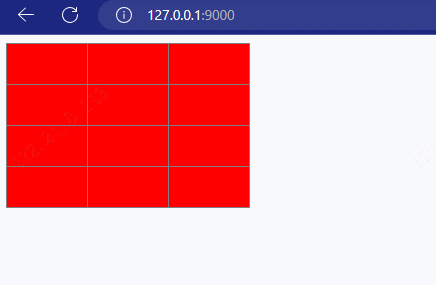
优化:
上面的HTML代码是在js文件里面编写的,没有语法高亮、没有代码提示,编写起来非常不方便,有没有办法能够解决这个痛点呢?
可以将html代码单独放到一个html文件里面来编写,使用fs模块来读取这个HTML文件,并作为返回结果返回。
xxxxxxxxxx561<!-- table.html文件 -->2<html lang="en">4 <head>5 <meta charset="UTF-8" />6 <meta http-equiv="X-UA-Compatible" content="IE=edge" />7 <meta name="viewport" content="width=device-width, initial-scale=1.0" />8 <title>Document</title>9 <style>10 table {11 border-collapse: collapse;12 }13 td {14 padding: 20px 40px;15 }16 tr:nth-child(odd) {17 background-color: lightsalmon;18 }19 tr:nth-child(even) {20 background-color: lightblue;21 }22 </style>23 </head>24 <body>25 <table border="1">26 <tr>27 <td></td>28 <td></td>29 <td></td>30 </tr>31 <tr>32 <td></td>33 <td></td>34 <td></td>35 </tr>36 <tr>37 <td></td>38 <td></td>39 <td></td>40 </tr>41 <tr>42 <td></td>43 <td></td>44 <td></td>45 </tr>46 </table>47 <script>48 let tds = document.querySelectorAll("td");49 tds.forEach((item) => {50 item.onclick = function () {51 this.style.backgroundColor = "red";52 };53 });54 </script>55 </body>56</html>
xxxxxxxxxx111const http = require("http")2const fs = require("fs")34http.createServer((request,response) => {5 let html = fs.readFileSync(__dirname + "/table.html")6 response.end(html);// response.end()的参数可以是Buffer,也可以是字符串7})89http.listen(9000,()=>{10 console.log("服务启动,端口号9000监听中...")11})这样做还有一个好处,就是更改了html文件里面的代码,不用重启服务器,当重新发送请求的时候,就会返回更改的内容。为什么呢?因为发起请求的时候,fs会重新读取HTML里面的内容,那么返回的就是最新的内容了。
11.网页资源的基本加载过程


网页资源的加载都是循序渐进的,首先获取 HTML 的内容, 然后解析 HTML ,再发送其他资源的请求(这就是为什么css、js、图片等静态资源都放在html标签里面进行获取),如 CSS,Javascript,图片 等(这些请求的发送是并行的,并没有绝对的先后之分)。 理解了这个内容对于后续的学习与成长有非常大的帮助。
11.1 扩展练习:
在10.1练习中,HTML文件里面写了CSS和JS,现在要求将css和js代码全部提取到单独的文件中,在HTML文件中引入这些文件,达到同样的效果,怎么做?
分析:将css用link标签导入,js用script标签导入,看效果:
xxxxxxxxxx381<!-- table.html -->2<html lang="en">4 <head>5 <meta charset="UTF-8" />6 <meta http-equiv="X-UA-Compatible" content="IE=edge" />7 <meta name="viewport" content="width=device-width, initial-scale=1.0" />8 <title>Document</title>9 <!-- 引入css文件 -->10 <link rel="stylesheet" href="./index.css">11 </head>12 <body>13 <table border="1">14 <tr>15 <td></td>16 <td></td>17 <td></td>18 </tr>19 <tr>20 <td></td>21 <td></td>22 <td></td>23 </tr>24 <tr>25 <td></td>26 <td></td>27 <td></td>28 </tr>29 <tr>30 <td></td>31 <td></td>32 <td></td>33 </tr>34 </table>35 <!-- 引入js文件 -->36 <script src="./index.js" type="text/javascript"></script>37 </body>38</html>xxxxxxxxxx141/* index.css */23table {4 border-collapse: collapse;5}6td {7 padding: 20px 40px;8}9tr:nth-child(odd) {10 background-color: lightsalmon;11}12tr:nth-child(even) {13 background-color: lightgoldenrodyellow;14}xxxxxxxxxx81// index.js23let tds = document.querySelectorAll("td");4tds.forEach((item) => {5 item.onclick = function () {6 this.style.backgroundColor = "red";7 };8});服务器代码不需要变化,引入的还是html文件,实际效果是:

这一看就是css代码没有导入,推测js代码也没有导入。但是文件是请求并返回了的啊:

但是仔细看一下index.css和index.js返回的内容:


可以看到css、js文件的响应结果都是html的代码,为什么?因为请求url虽然不同:



但是走的都是这段代码。
xxxxxxxxxx41const server = http.createServer((request,response) => {2 let html = fs.readFileSync(__dirname + "/table.html")3 response.end(html)4})上述代码并没有对request请求做处理,所以返回的都是html。可以根据request.url的pathname判断,返回不同的结果。
xxxxxxxxxx251const http = require("http");2const fs = require("fs");34const server = http.createServer((request, response) => {5 const { url } = request;6 let newURL = new URL(url, "http://127.0.0.1");7 let pathname = newURL.pathname;8 if (pathname === "/") {9 let html = fs.readFileSync(__dirname + "/table.html");10 response.end(html);11 } else if (pathname === "/index.css") {12 let css = fs.readFileSync(__dirname + "/index.css");13 response.end(css);14 } else if (pathname === "/index.js") {15 let js = fs.readFileSync(__dirname + "/index.js");16 response.end(js);17 } else {18 response.statusCode = 404;19 response.end("404 Not Found");20 }21});2223server.listen(9001, () => {24 console.log("服务器已启动,端口号9001监听中...");25});再访问OK。
这个案例看上去很简单,但其实很重要,它已经做到了前端开发服务器的基本功能了,而且可以做到热更新,我如果编写html文件,完全可以用这个服务器来查看实际效果,这实际上就达到了vscode中的open with live server这个插件的基本功能了。
这是一个重要的开始,不管是vue/cli、create-react-app还是vite,这些脚手架都是从这个简单的服务器开始的。
我又想到了,平时最常使用的npm run dev和npm run build命令,就是重点依靠fs模块,读取和写入操作,真的是有点熟悉的感觉了。
12.静态资源服务
静态资源是指 内容长时间不发生改变的资源 ,例如图片,视频,CSS 文件,JS文件,HTML文件,字体文件等。
动态资源是指 内容经常更新的资源 ,例如百度首页,网易首页,京东搜索列表页面等。
练习:搭建静态资源服务,需求如下:

分析:这个需求并不是将css、image都放到一个html文件里面请求(也就是说不用在html文件里面引入css或者写img标签),而是直接在浏览器地址栏中使用http://127.0.0.1:9000/index.html、http://127.0.0.1:9000/css/app.css等这种url的方式直接请求,能够得到文件内容即可。其实这种效果我们之前已经实现过了。

xxxxxxxxxx251const http = require("http");2const fs = require("fs");34const server = http.createServer((request, response) => {5 const { url } = request;6 const { pathname } = new URL(url, "http://127.0.0.1");78 if (pathname === "/index.html") {9 let html = fs.readFileSync(__dirname + "/page" + pathname);10 response.end(html);11 } else if (pathname === "/css/index.css") {12 let css = fs.readFileSync(__dirname + "/page" + pathname);13 response.end(css);14 } else if (pathname === "/images/logo.png") {15 let img = fs.readFileSync(__dirname + "/page" + pathname);16 response.end(img);17 } else {18 response.statusCode = 404;19 response.end("404 Not Found");20 }21});2223server.listen(9000, () => {24 console.log("服务已启动,端口号9000监听中...");25});但是里面有太多的if...else if的判断条件,如果我要添加文件,就要添加判断条件,有没有办法去掉这么多判断条件呢?可以,因为fs读取的文件路径和pathname是有关联的,统一构造文件地址即可。
xxxxxxxxxx231const http = require("http");2const fs = require("fs");34const server = http.createServer((request, response) => {5 // 设置响应头6 response.setHeader("content-type", "text/html;charset=utf8");7 const { url } = request;8 const { pathname } = new URL(url, "http://127.0.0.1");9 // 设置文件读取路径10 let filePath = __dirname + "/page" + pathname;11 fs.readFile(filePath, (err, data) => {12 if (err) {13 response.statusCode = 500;14 response.end("文件读取失败");15 return;16 }17 response.end(data);18 });19});2021server.listen(9000, () => {22 console.log("服务已启动,端口号9000监听中...");23});
这个练习其实生动的展示了tomcat服务器开启服务的过程。项目打包的文件放到一个文件夹里面,一般是我使用npm run build生成的dist文件夹里面的文件,内容是这些:
放到tomcat的webapps里面。
访问就输入
http://172.21.21.64:8080/info-collector来访问。tomcat会帮助返回文件夹里面的内容。这个过程现在完全可以用nodejs来实现了,一定要找时间自己实现一下。
其实这里要搞清楚一点,在上面的案例中,其实是根据路径pathname的不同,返回不同的文件的。但是在tomcat里面,路径都是一样的,那该怎么返回文件呢?
这一点其实很好解释,我使用的路径是
/info-collector,这个路径名返回的是index.html文件,其余的文件都在html文件里面引入了,所以在html文件里面引入别的文件的时候,强烈建议写绝对路径,而vue生成的html文件里面就是这样做的。
那么服务端获取到的文件pathname就自动带上了
/info-collector,我也不需要进行特殊处理了。直接读取即可。不会有任何影响,只要服务端代码能够根据地址找到正确的文件即可。
在学习vue的时候,我们知道有hash模式和history模式,在发布项目之后,我总是给别人的访问url上带上了
/#/,比如说:http://172.21.21.64:8080/info-collector/#/,其实#/不需要加上,因为这部分内容是vue帮我们生成的,我直接在地址栏里面输入``,返回的是:
而这个html文件中,引入了css、js、图片等文件:
所以服务器会请求这些文件,就像上面的案例展示的一样。
瞬间感觉vue的一部分原理我搞清楚了。嘿嘿。






自己用nodejs创建服务器,部署实际项目。

xxxxxxxxxx371// 3.js23const http = require("http");4const fs = require("fs");56const server = http.createServer((request, response) => {7 // 按照之前的案例,在读取失败时返回“文件读取失败”,为了解决中文乱码问题,设置了下面的header。但是这个header就限定了文件的解码规则,所以css等文件请求并返回成功了,但样式没有显示出来。我在这里注销这句代码,成功解决了样式问题。但是也可以设置多个header,来正确解析css、图片等资源。参考:https://blog.csdn.net/helgeal/article/details/1206426788 // response.setHeader("content-type", "text/html;charset=utf-8");9 const { url } = request;10 const { pathname } = new URL(url, "http://127.0.0.1");11 // 这里的/dist/其实就相当于tomcat里面的文件夹名,可以获取用户自定义的文件夹名,放到这里来,这就解决了我上面的疑问了。12 // index.html文件需要单独解析。因为引入html文件时,url上并没有index.html,所以读取文件的路径无法直接拼接。而其余的文件都有具体的路径。13 if (pathname === "/dist/") {14 fs.readFile(__dirname + "/dist/index.html", (err, data) => {15 if (err) {16 response.statusCode = 500;17 response.end("file read fail");18 return;19 }20 response.end(data);21 });22 } else {23 let filePath = __dirname + pathname;24 fs.readFile(filePath, (err, data) => {25 if (err) {26 response.statusCode = 500;27 response.end("file read fail");28 return;29 }30 response.end(data);31 });32 }33});3435server.listen(9000, () => {36 console.log("服务已启动,端口9000监听中...");37});输入http://127.0.0.1:9000/dist/进行访问,效果非常OK:
尝试将项目包文件夹名改为info-collector,相应的代码改一下,访问也是OK的。
上面的是前端项目的部署,其实后端项目的部署也是一样的,也是部署打包之后的文件,只需要找到主文件即可。真的是学到了一个重要的知识点。
12.1 网站根目录或静态资源目录
HTTP 服务在哪个文件夹中寻找静态资源,哪个文件夹就是 静态资源目录 ,也称之为 网站根目录。
这一点必须理解清楚,因为写server的时候,可能要用到比较灵活的网站根目录,上面案例中,在读取文件的时候,可以定义一个变量
let root = __dirname + "/pages",作为网站的根目录,读取文件时拼接上pathname就行了。那么当根目录需要修改的时候,只需要修改root变量即可。
思考:vscode 中使用 live-server 访问 HTML 时, 它启动的服务中网站根目录是谁?
答案:是vscode打开的文件夹。
做一个实验验证一下,使用live-server打开test/a/b/c/index.html,看一下浏览器地址栏的url。
可以看到,网站的根目录确实是vscode打开的文件夹,在这里就是test文件夹,地址标记就是a前面那个
/。


12.2 网页中的 URL
网页中的 URL 主要分为两大类:相对路径与绝对路径。
注意:这里说的是网页中的URL,指的就是html文件中的url,具体就是html标签里面使用的url。
12.2.1 绝对路径
绝对路径可靠性强,而且相对容易理解,在项目中运用较多。
| 形式 | 特点 | 备注 |
|---|---|---|
| http://atguigu.com/web | 直接向目标资源发送请求,容易理解。网站的外链会用到此形式。 | 完整url |
| //atguigu.com/web | 与当前页面 URL 的协议拼接形成完整 URL 再发送请求。大型网站用的比较多。 | url省略了http协议 |
| /web | 与当前页面 URL 的协议、主机名、端口拼接形成完整 URL 再发送请求。中小型网站用的比较多。 | url省略了http协议、域名、端口号 |
示例:
xxxxxxxxxx171<html lang="en">3<head>4 <meta charset="UTF-8">5 <meta name="viewport" content="width=device-width, initial-scale=1.0">6 <title>Document</title>7</head>8<body>9 <a href="https://www.baidu.com/">百度</a>1011 <!-- 为什么可以正常访问?因为会与当前页面的http协议进行拼接,再进行访问。 -->12 <a href="//jd.com">京东</a>1314 <!-- 这种形式用的很多,不仅仅是a标签用,link、script标签都可以这样用。这样就避免了域名更换带来的影响。这种形式我其实一直在用,但是不知道原理,现在知道了。 -->15 <a href="/search">搜索</a>16</body>17</html>效果:
12.2.2 相对路径
相对路径在发送请求时,需要与当前页面 URL 路径进行 计算 ,得到完整 URL 后,再发送请求,学习阶段用的较多。
示例:假如当前网页 url 为 http://www.atguigu.com/course/h5.html,当前文件夹就是course文件夹,下面的相对路径形式的最终的url就得到这些结果:
| 形式 | 最终的URL | 备注 |
|---|---|---|
| ./css/app.css | http://www.atguigu.com/course/css/app.css | 表示当前文件夹下的资源 |
| js/app.js | http://www.atguigu.com/course/js/app.js | 表示当前文件夹下的资源 |
| ../img/logo.png | http://www.atguigu.com/img/logo.png | 表示当前文件夹同一层级的文件夹img下的logo.png |
| ../../mp4/show.mp4 | http://www.atguigu.com/mp4/show.mp4 | 因为 ../ 已经到了最顶层了,所以2个 ../ 效果只是一个 ../的效果 |
到底应该使用相对路径还是绝对路径,需要总结一下,上面说相对路径在学习阶段用的比较多,注意这句话的前提是:网页里面的URL,也可以理解为html文件里面的url。
但是我目前做前后端分离开发,界面都是使用UI库来开发,vue/react等,在里面应该使用那种路径呢?
在vue组件里面,引入组件、标签里面引入文件;里面的js文件,引入别的js、css等文件,都可以使用相对路径,也可以使用
@/开头,表示src文件夹。也可以使用绝对路径,但是这个绝对路径的根目录就是public文件夹了,除非你引入的文件存放在public文件夹里面,否则不要使用绝对路径。在react组件里面,引入组件、js文件、css文件等,都是使用相对路径。前端开发使用相对路径没有问题,这是因为vue/react框架会为我们处理这些相对路径,打包之后的文件中,都会使用绝对路径。
vue/react框架里面有html文件,在这里面推荐使用绝对路径,因为里面的一些资源都放在了公共文件夹里面了,到时候试一下就知道了。
12.2.3 网页中使用 URL 的场景小结
包括但不限于如下场景:
- a 标签 href
- link 标签 href
- script 标签 src
- img 标签 src
- video audio 标签 src
- form 中的 action
- AJAX 请求中的 URL
12.3 设置资源类型(mime类型)
媒体类型(通常称为 Multipurpose Internet Mail Extensions 或 MIME 类型 )是一种标准,用来表示文档、文件或字节流的性质和格式。
xxxxxxxxxx21mime 类型结构: [type]/[subType]2例如: text/html text/css image/jpeg image/png application/json
HTTP 服务可以设置响应头 Content-Type 来表明响应体的 MIME 类型,浏览器会根据该类型决定如何处理资源。
下面是常见文件对应的 mime 类型:
xxxxxxxxxx91html: 'text/html',2css: 'text/css',3js: 'text/javascript',4png: 'image/png',5jpg: 'image/jpeg',6gif: 'image/gif',7mp4: 'video/mp4',8mp3: 'audio/mpeg',9json: 'application/json'
对于未知的资源类型,可以选择
application/octet-stream类型,浏览器在遇到该类型的响应时,会对响应体内容进行独立存储,也就是我们常见的下载效果
练习:对12.静态资源服务的练习,对不同的文件设置资源类型。
xxxxxxxxxx251const path = require("path");23const mimes = {4 html: 'text/html',5 css: 'text/css',6 js: 'text/javascript',7 png: 'image/png',8 jpg: 'image/jpeg',9 gif: 'image/gif',10 mp4: 'video/mp4',11 mp3: 'audio/mpeg',12 json: 'application/json' 13}1415const {url} = req;16let newUrl = new URL(url,"http://127.0.0.1");17let {pathname} = newUrl;18const {extname} = path.parse(pathname);19let type = mimes[extname.slice(1)]20if(type){21 response.setHeader("content-type",type)22} else {23 // 对于未知类型,设置成 application/octet-stream24 response.setHeader("content-type","application/octet-stream")25}需求:解决乱码问题。在js、css文件中,如果有中文,是会出现乱码的,之前我们解决乱码问题的方式是response.setHeader("content-type","text/html;charset=utf-8"),但这里是js、css等文件,很明显不能设置为text/html,需要单独设置,其实也很简单,在得到具体的type后面拼接上;charset=utf-8就行了。
xxxxxxxxxx581const http = require("http");2const fs = require("fs");3const path = require("path");4const mimes = {5 html: "text/html",6 css: "text/css",7 js: "text/javascript",8 png: "image/png",9 jpg: "image/jpeg",10 git: "image/gif",11 mp4: "video/mp4",12 mp3: "audio/mpeg",13 json: "application/json",14};1516const server = http.createServer((req, res) => {17 const { url } = req;18 let newUrl = new URL(url, "http://127.0.0.1");19 let { pathname } = newUrl;20 let { extname } = path.parse(pathname);21 if (extname) {22 let realName = extname.slice(1);23 let type = mimes[realName];24 if (type) {25 if (realName === "html" || realName === "css" || realName === "js") {26 res.setHeader("content-type", type + ";charset=utf-8;");27 } else {28 res.setHeader("content-type", type);29 }30 } else {31 res.setHeader("content-type", "application/octet-stream");32 }33 }34 if (url === "/info-collector") {35 fs.readFile(__dirname + "/info-collector/index.html", (err, data) => {36 if (err) {37 res.statusCode = 500;38 res.end("file read fail");39 return;40 }41 res.end(data);42 });43 } else {44 fs.readFile(path.resolve(__dirname, "info-collector" + url), (err, data) => {45 if (err) {46 res.statusCode = 500;47 res.end("file read fail");48 return;49 }50 res.end(data);51 });52 }53});5455server.listen(9000, () => {56 console.log("服务已启动,端口9000监听中...");57});58疑问:当没有设置html的乱码兼容时,HTML文件里面的中文并不会是乱码,这是为什么呢?
因为HTML文件里面有一句代码<meta charset="UTF-8">,已经设置了字符。那如果我在服务器代码里面设置了HTML的响应头呢,以哪个为主呢?
可以自己改一下代码,答案是设置的html响应头优先级更高一些。
小节:其实网站的css、js等文件的响应头没有必要加上;charset=utf-8,因为这些文件虽然返回的时候中文乱码了,但是这些文件加载到html中之后,会按照html的字符集来解析,而一般html的字符集都设置为了utf-8,所以不会在网页中出现乱码。
完善错误处理:
还是上面的案例,在fs读取文件的时候,可能有多种错误类型,要根据不同的错误类型返回不同的信息。

12.4 GET 和 POST 请求场景小结
GET 请求的情况:
- 在地址栏直接输入 url 访问
- 点击 a 链接
- link 标签引入 css
- script 标签引入 js
- img 标签引入图片
- form 标签中的 method 为 get (不区分大小写)
- ajax 中的 get 请求
POST 请求的情况:
- form 标签中的 method 为 post(不区分大小写)
- AJAX 的 post 请求
13.GET和POST请求的区别
GET 和 POST 是 HTTP 协议请求的两种方式。主要有如下几个区别:
- 作用不同。GET 主要用来获取数据,POST 主要用来提交数据。
- 参数位置不同。GET 带参数请求是将参数缀到 URL 之后,在地址栏中输入 url 访问网站就是 GET 请求,POST 带参数请求是将参数放到请求体中。
- 安全性不同。POST 请求相对 GET 安全一些,因为在浏览器中参数会暴露在地址栏。
- 请求大小限制不同。GET 请求大小有限制,一般为 2K,而 POST 请求则没有大小限制。
05_Node.js 模块化
1.介绍
1.1 什么是模块化与模块 ?
将一个复杂的程序文件依据一定规则(规范)拆分成多个文件的过程称之为 模块化。
其中拆分出的 每个文件就是一个模块 ,模块的内部数据是私有的,不过模块可以暴露内部数据以便其他模块使用。
1.2 什么是模块化项目 ?
编码时是按照模块一个一个编码的, 整个项目就是一个模块化的项目。
1.3 模块化好处
下面是模块化的一些好处:
- 防止命名冲突
- 高复用性
- 高维护性
2.模块暴露数据
2.1 模块初体验
可以通过下面的操作步骤,快速体验模块化
- 创建 me.js
xxxxxxxxxx71//声明函数2function tiemo(){3 console.log('贴膜....');4}56//暴露数据7module.exports = tiemo;- 创建 index.js
xxxxxxxxxx51//导入模块2const tiemo = require('./me.js');34//调用函数5tiemo();执行node index.js,查看效果:

2.2 暴露数据
模块暴露数据的方式有两种:
- module.exports = value
- exports.name = value
使用时有几点注意:
- module.exports 可以暴露
任意类型的数据。- 不能使用
exports = value的形式暴露数据。模块内部 module 与 exports 的隐式关系是这样的:
exports = module.exports = {},require 返回的是目标模块中module.exports的值。

xxxxxxxxxx181// me.js2function tiemo(){3 console.log("贴膜")4}56function niejiao(){7 console.log("捏脚")8}910// 使用 module.exports 来暴露数据11module.exports = {12 tiemo,13 niejiao14}1516// 使用 exports.name 来暴露数据。注意:不能使用 exports = value 这种形式来暴露数据,这样不会报错,但是取不到数据。17exports.tiemo = tiemo18exports.niejiao = niejiaoxxxxxxxxxx31// index.js 在测试时,要将 me.js 里面的 module.exports 和 exports 分别注释来看效果。2const me = require("./me.js")3console.log(me)
3.导入(引入)模块
在模块中使用 require 传入文件路径即可引入文件。
xxxxxxxxxx11const test = require('./me.js');require 使用的一些注意事项:
对于自己创建的模块,导入时路径建议写
相对路径,且不能省略./和../。(在讲解fs模块的时候,因为相对路径会受到工作目录的影响,老师是强烈建议使用绝对路径的,这里为什么推荐使用相对路径呢?因为在使用require引入时,不会受到工作目录的影响,并且相对路径写起来比较简单。)在导入
js和json文件时,可以不用写后缀(如果导入的js文件和json文件同名,在导入时都省略了后缀,那导入的是哪个文件呢?导入的是js文件。),导入c/c++编写的node扩展文件也可以不写后缀,但是一般用不到。如果导入其他类型的文件,会以
js文件进行处理。如果导入的路径是个文件夹(就是经常使用的导入第三方模块的用法),则会
首先检测该文件夹下package.json文件中main属性对应的文件,如果存在则导入,如果文件不存在会报错。如果 main 属性不存在,或者 package.json 不存在,则会尝试导入文件夹下的
index.js和index.json,如果没找到,就会报错。案例:

xxxxxxxxxx21// 引入文件夹/module/app.js2module.exports = "我是一个模块"xxxxxxxxxx51// 引入文件夹/module/package.json2// 如果main属性指向的文件地址与package.json同层级,可以省略 ./3{4"main":"./app.js"5}xxxxxxxxxx41// 引入文件夹/index.js2const m = require("./module")34console.log(m)运行
node index.js
导入 node.js 内置模块时,直接 require 模块的名字即可,无需加
./和../。
4.导入模块的基本流程
这里我们介绍一下 require 导入 自定义模块 的基本流程
- 将相对路径转为绝对路径,定位目标文件
- 缓存检测
- 读取目标文件代码
- 包裹为一个函数并执行(自执行函数)。(通过
arguments.callee.toString()查看自执行函数) - 缓存模块的值
- 返回
module.exports的值

导入模块的伪代码:
xxxxxxxxxx371/**2 * 伪代码,不过代码是按照基本流程写出来了,我要记住这个流程可以怎么写,这个还是很重要的一个思路。3 */45// file是相对路径的形参。6function require(file){7 //1. 将相对路径转为绝对路径,定位目标文件8 let absolutePath = path.resolve(__dirname, file);9 //2. 缓存检测。caches是存在一个地方的,也许是全局变量,不需要管这个地方是什么,直接读取判断即可。10 if(caches[absolutePath]){11 return caches[absolutePath];12 }13 //3. 读取文件的代码14 let code = fs.readFileSync(absolutePath).toString();15 //4. 包裹为一个函数 然后执行16 17 let module = {};18 let exports = module.exports = {};19 // 最难理解的就是下面这个函数,这个函数是怎么来的?这里是伪代码,老师通过在模块文件中写入 console.log(arguments.callee.toString()); 来输出这段代码,然后包裹成一个自执行函数。自执行函数的函数体内容,就是上面读取的code内容。20 (function (exports, require, module, __filename, __dirname) {21 const test = {22 name: '尚硅谷'23 }24 25 module.exports = test;26 27 //输出28 console.log(arguments.callee.toString());29 })(exports, require, module, __filename, __dirname)30 31 //5. 缓存结果。这里只是伪代码,上面只定义了module,并没有具体处理module的过程,知道思路即可。32 caches[absolutePath] = module.exports;33 //6. 返回 module.exports 的值34 return module.exports;35}3637const m = require('./me.js');感想:
如何将已经学过的东西,组合起来写成工具解决问题,这个我几乎没有经验、也没有这种想法(我说的是工具,不是项目),今天学习Nodejs的require的基本流程,伪代码基本写完了流程,是按照上面的中文流程写出来的,我能够做到吗?可能刚开始很难,但要慢慢的去做。
5.CommonJS 规范
module.exports 、 exports 以及 require 这些都是 CommonJS 模块化规范中的内容。
而 Node.js 是实现了 CommonJS 模块化规范,二者关系有点像 JavaScript 与 ECMAScript。